
Using the Uberduck API
In this post, you'll learn to use the Uberduck API to generate speech and song and convert between voices.
This post will cover how to generate speech and singing using text-to-speech and voice-to-voice with the Uberduck API. You can access the API docs here or interactively explore here and here.
Covered in this guide
- Getting started with accessing the API
- Viewing the list of available voices for text-to-speech and voice-to-voice
- Generating speech from text
- Converting speech from one voice to another
- Generating rap
The examples in this guide are given in Python, but you can access the API using a language of your choosing.
The endpoints accessible via our API
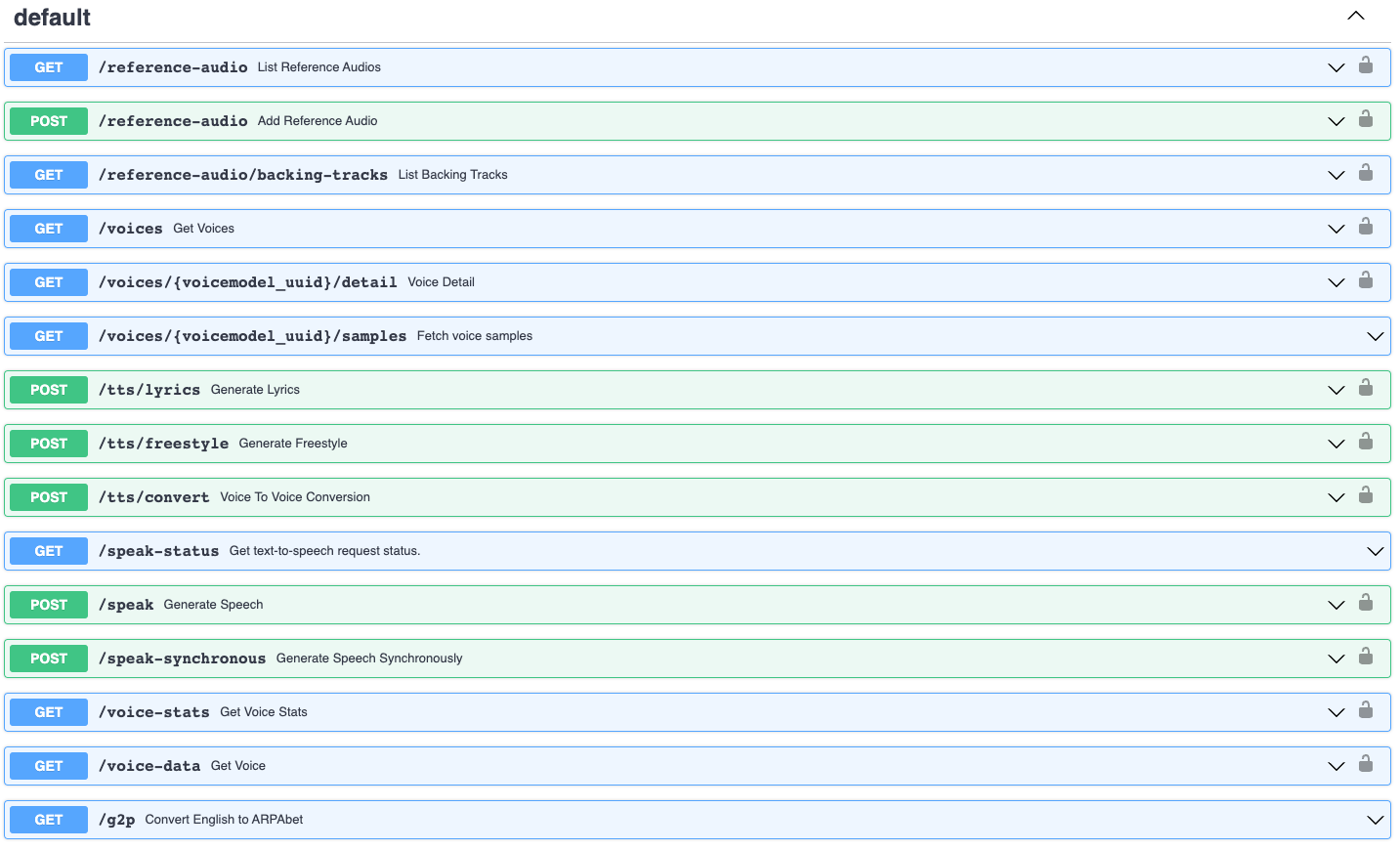
🦆 Let's get quacking!
1. Getting started
Creating an Uberduck account
The first thing you will need to do is sign up for an Uberduck account! Go to the signup page and create an account.
Creating an API key
After you've created an account, go to our account management page.
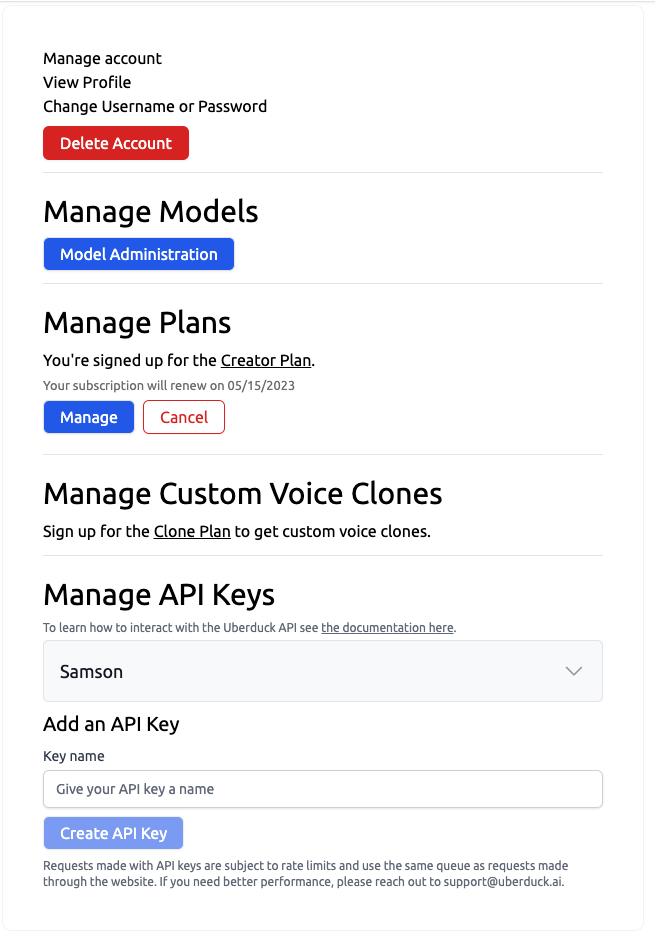
Create an API key and write down the secret key in a secret place. You can create as many API keys as you'd like, but can only view the secret key when you create it.
You'll now be able to access the API. For unlimited access and access to commercial use voices, purchase a plan at our pricing page.
Checking the API is functional
2. Viewing available voices
You may then view the list of available voices for text-to-speech and voice-to-voice by making an HTTP GET request to the /voices endpoint.
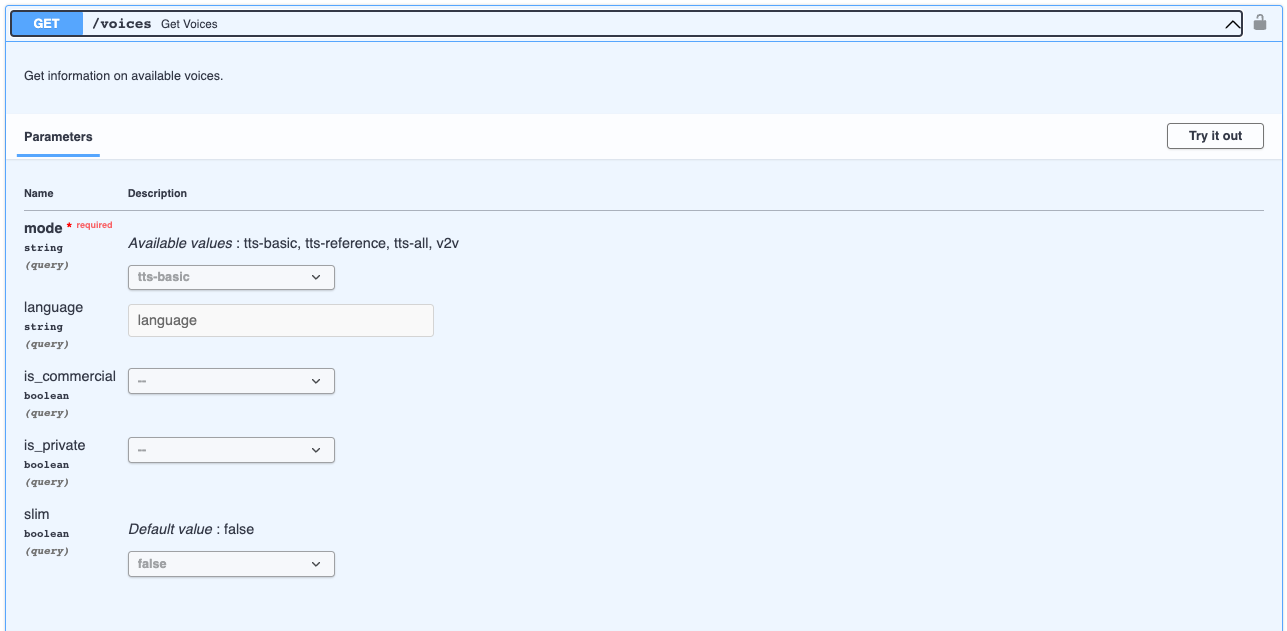
Text-to-speech
Voice-to-voice
3. Generating speech from text
You can then select a voice and generate speech from text. This is done by making a post request to the /speak endpoint. This is an asynchronous request - for synchronous support, use /speak-synchronous.
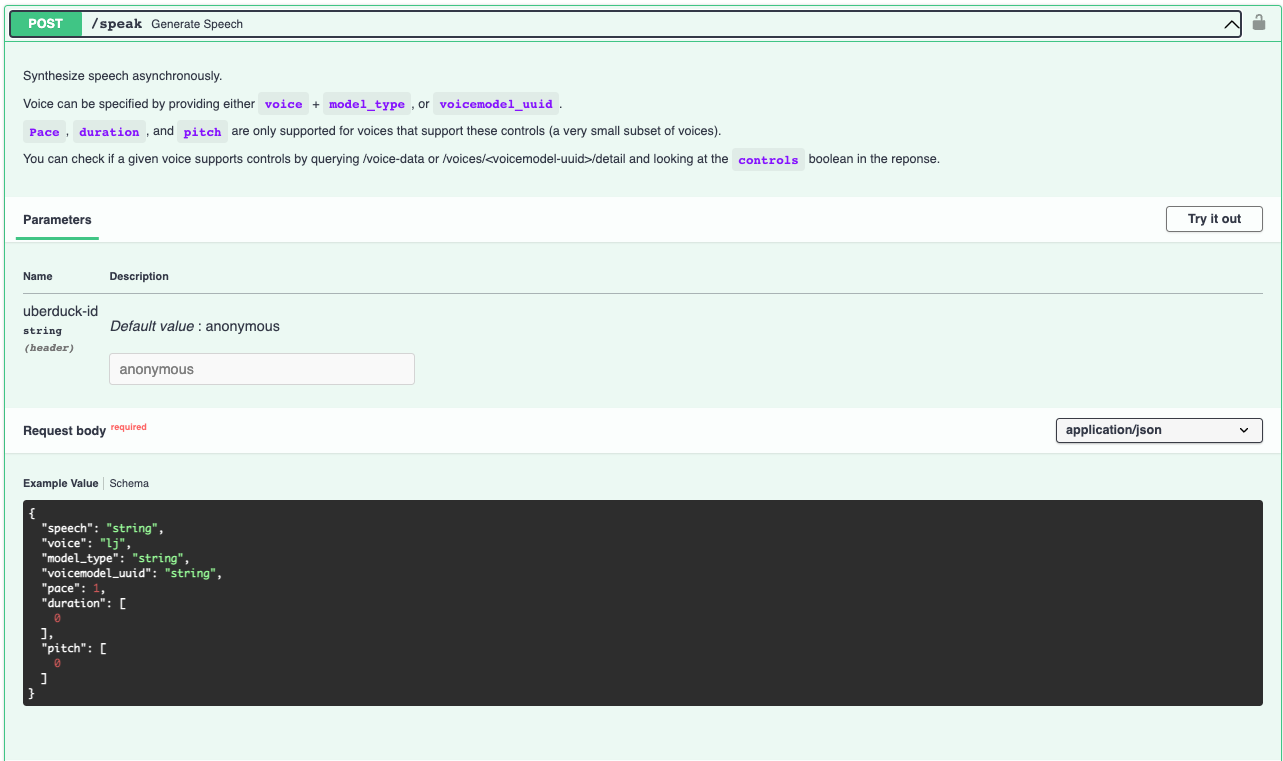
Choosing a voice and text
The best way to specify a voice is by using a voicemodel_uuid returned from /voices. Let's use a text-to-speech Tacotron2 trained on LJ Speech. For historical purposes not covered here, this voice will be reading a quote from General Sherman.
Making a speak request
Checking the status of your speak request
Since the /speak endpoint is asynchronous, we need to check its status.
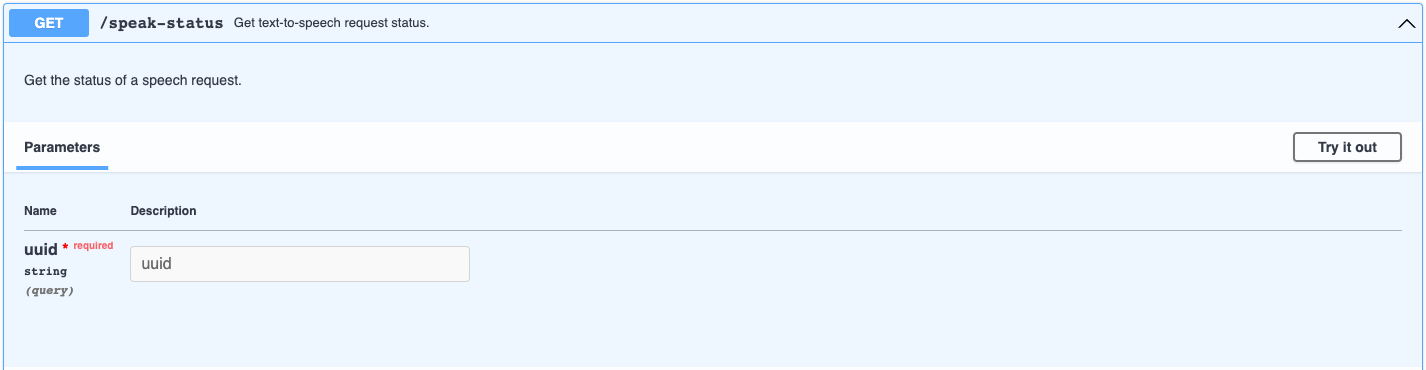
Checking the output of your speak request
If your use case is able to support using the url directly, the url containing the audio output may be sufficient.
Downloading the output of your speak request
For other applications, it may be preferable to download the output.
4. Converting speech from voice to voice
In addition to text-to-speech models, Uberduck supports user-contributed voice-to-voice models. The requisite steps are to specify a voice model for conversion, upload the audio to be converted, and convert the audio. We can get a list of available models using the method in Section 2 and so won't cover that again here.
Uploading your audio
You will need to upload audio to our servers to convert. This tutorial uses the output we downloaded earlier, but you may use any audio file shorter than 5 minutes.
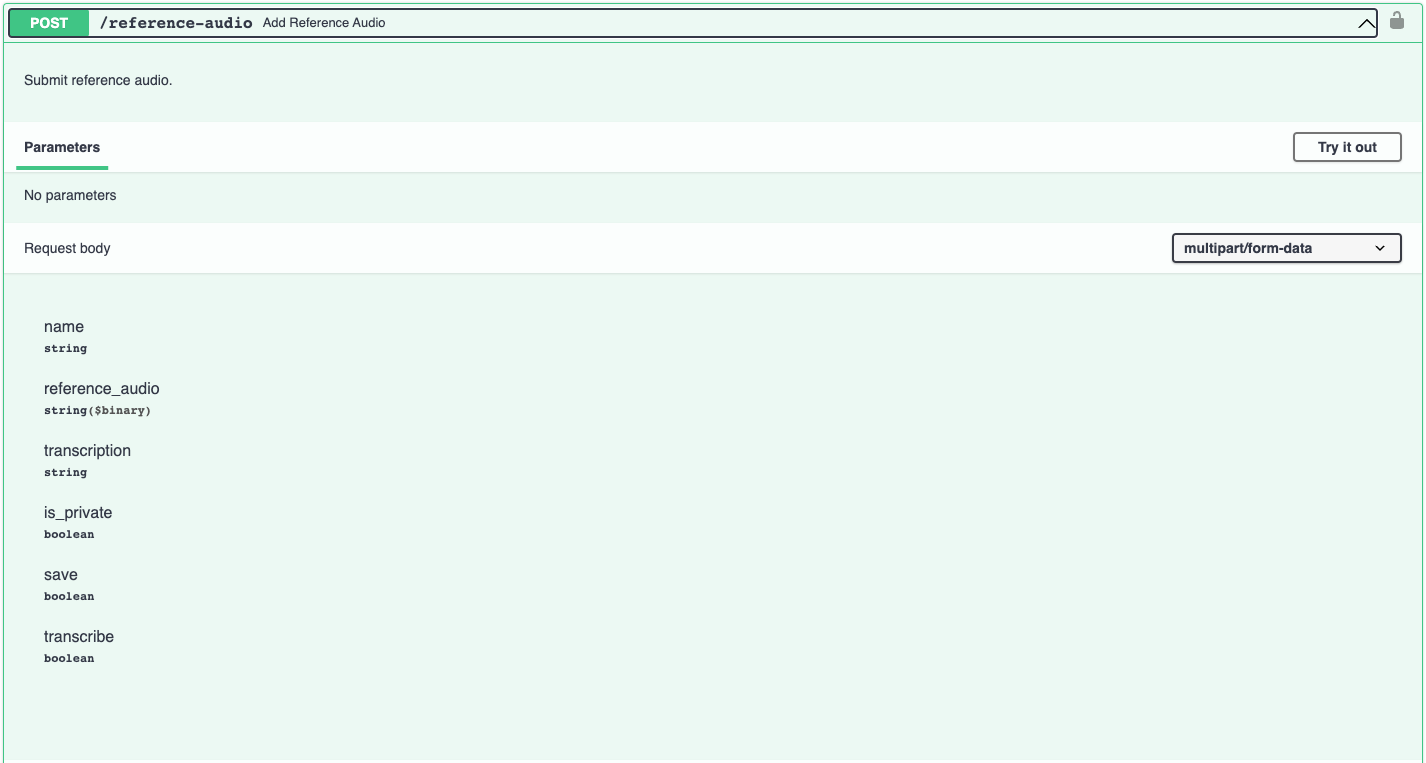
Converting audio
Once your audio is uploaded, you can convert it from voice to voice. Let's convert the audio to Grimes' voice.
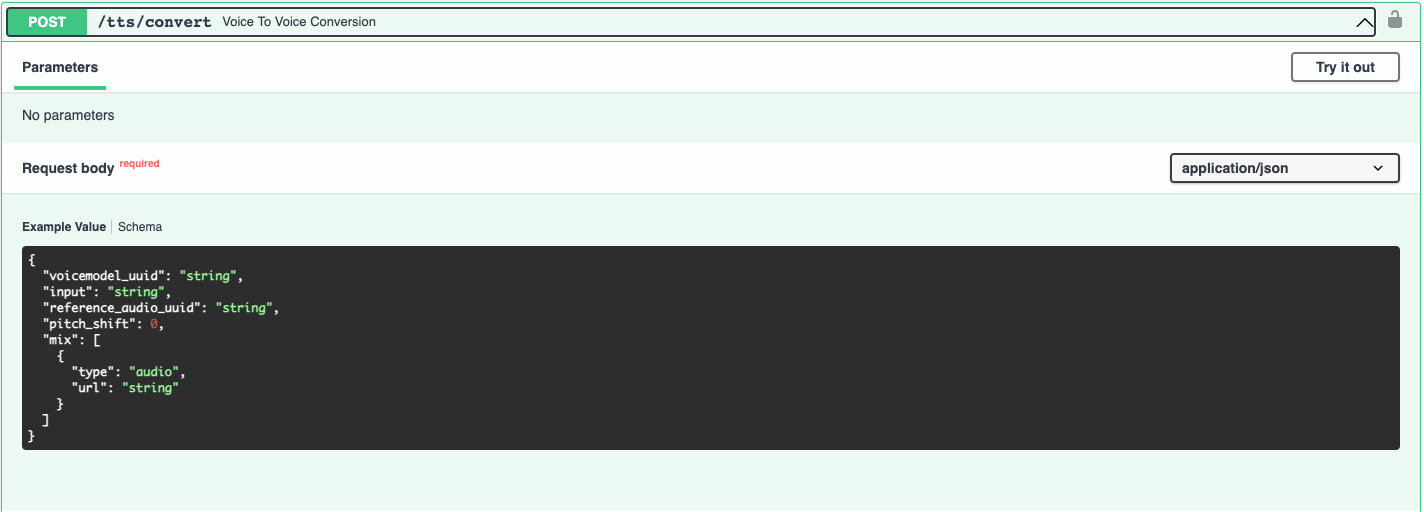
The audio will be output with the prosody and pitch of the original speaker (although it is possible to change the pitch as a parameter as well).
5. Generating Rap
The rap generator ensures that each line is distributed over its own measure at the specified beats per minute (bpm). You may supply your own lyrics, or generate them with the Uberduck lyrics generator. You may also add specify a Uberduck-provided backing track. However, you may also access the a cappella directly and mix with a backing track yourself.
User-specified lyrics
Note that the lyrics parameter is a list of lists of strings. Each verse is passed as a list of strings, so the below example specifies a rap with a single verse.
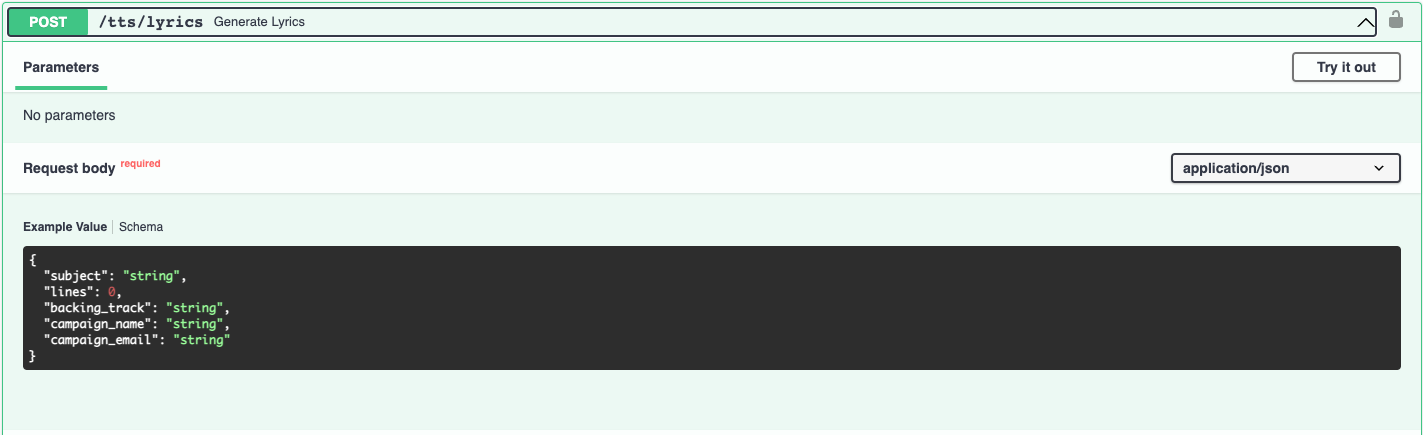
Adding a backing track
Uberduck provides a library of backing tracks with preset alignment to the rap and multiverse structure. It is important to match the bpm between the backing track and the audio. You may view the list of available backing tracks by making a request to the GET reference-audio/backing-tracks endpoint.
Once you have the uuid of the backing track, you can specify this in your post request to tts/freestyle.
Lyrics generation
Uberduck also provides the ability to generate lyrics programmatically. In order to generate lyrics automatically, Uberduck uses a wrapper around the OpenAI API with some prompt engineering. We can use this to generate lyrics about a given subject.
Automated rap generation
We can also generate lyrics automatically to fit a given backing track. This is the end to end song generator used on Uberduck. This uses the default voice, but additional voices may be specified as well.
Thank you!
If you enjoyed this article, let us know in our Discord or email me at s@uberduck.ai.